

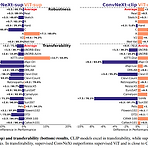
 ConvNet vs ViT 비교 논문
ConvNet vs ViT 비교 논문
https://arxiv.org/abs/2311.09215 ConvNet vs Transformer, Supervised vs CLIP: Beyond ImageNet Accuracy Modern computer vision offers a great variety of models to practitioners, and selecting a model from multiple options for specific applications can be challenging. Conventionally, competing model architectures and training protocols are compared by their c arxiv.org 대충 결론만 봄 나중에 다시 읽어보자(과연?)
https://github.com/mcc-wh/token GitHub - MCC-WH/Token: Official implementation of the AAAI 2022 paper "Learning Token-based Representation for Image Retrieval" Official implementation of the AAAI 2022 paper "Learning Token-based Representation for Image Retrieval" - MCC-WH/Token github.com 요새 해보고 싶은 건 너무 많고 번뜩 떠오른 것도 많은데 그러다보니 잊는 것들도 많이 생겨서 기록 1. 시밀러리티 뭔 식 사용하는지 논문, 코드 뜯어보기 2. 돌려보기
 docker compose 로 container 생성하며 shell에 attach하기
docker compose 로 container 생성하며 shell에 attach하기
https://stackoverflow.com/a/49647309/10386667 Interactive shell using Docker Compose Is there any way to start an interactive shell in a container using Docker Compose only? I've tried something like this, in my docker-compose.yml: myapp: image: alpine:latest entrypoint: /bin/sh stackoverflow.com docker compose run {서비스 이름} /bin/bash 만약 yaml 파일이 아래와 같이 작성돼있다면 {서비스 이름}에 app을 넣어주면 됨 stdin_open, tt..
https://stackoverflow.com/questions/2122706/detect-color-space-with-opencv detect color space with openCV how can I see the color space of my image with openCV ? I would like to be sure it is RGB, before to convert to another one using cvCvtColor() function thanks stackoverflow.com 있다면 방법 좀 알려주세요ㅠㅠ

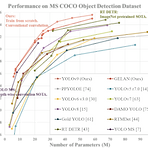 20240222 YOLOv9 가 공개되다.
20240222 YOLOv9 가 공개되다.
https://github.com/WongKinYiu/yolov9 GitHub - WongKinYiu/yolov9: Implementation of paper - YOLOv9: Learning What You Want to Learn Using Programmable Gradient Inform Implementation of paper - YOLOv9: Learning What You Want to Learn Using Programmable Gradient Information - WongKinYiu/yolov9 github.com https://arxiv.org/pdf/2402.13616.pdf X축이 Latency 면 어떻게 그려질지 궁금하다.
 Docker nvidia/cuda 이미지 기반으로 TensorRT 설치시 Depends: libnvinfer8 (= *) but * is to be installed 에러
Docker nvidia/cuda 이미지 기반으로 TensorRT 설치시 Depends: libnvinfer8 (= *) but * is to be installed 에러
nvcr.io/nvidia/cuda:11.8.0-cudnn8-devel-ubuntu22.04 이미지를 베이스 이미지로하여 8.6.0.12-1+cuda11.8 버전의 TensorRT 관련 라이브러리를 다운로드 받으니 다운로드가 안된다. What?! 어떤 건 다운로드가 되고 어떤 건 안된다. 기존에 8.5.3-1+cuda11.8 으로 다운로드 받는 명령어를 아래와 같이 실행했었어서, RUN \ apt-get update && \ apt-get install -y libnvinfer8=8.5.3-1+cuda11.8 \ libnvinfer-plugin8=8.5.3-1+cuda11.8 \ libnvparsers8=8.5.3-1+cuda11.8 \ libnvonnxparsers8=8.5.3-1+cuda11.8 \ ..
 META V-JEPA
META V-JEPA
https://ai.meta.com/blog/v-jepa-yann-lecun-ai-model-video-joint-embedding-predictive-architecture/ V-JEPA: The next step toward advanced machine intelligence Previous work had to do full fine-tuning, which means that after pre-training your model, when you want the model to get really good at fine-grained action recognition while you’re adapting your model to take on that task, you have to updat..
 Google Magika 파일 종류 인식을 AI로
Google Magika 파일 종류 인식을 AI로
https://opensource.googleblog.com/2024/02/magika-ai-powered-fast-and-efficient-file-type-identification.html Magika: AI powered fast and efficient file type identification Magika code and model are freely available starting today in Github under the Apache2 License. opensource.googleblog.com https://github.com/google/magika GitHub - google/magika: Detect file content types with deep learning Det..
- Total
- Today
- Yesterday
- ㅂ
- FairMOT
- C++ Deploy
- 백준
- 위상 정렬 알고리즘
- 단축키
- cosine
- 인공지능을 위한 선형대수
- 조합
- 순열
- 백준 1766
- 이분탐색
- PyCharm
- Lowest Common Ancestor
- 백준 11437
- 가장 긴 증가하는 부분 수열
- MOT
- 백준 11053
- 자료구조
- 백트래킹
- LCA
- 파이참
- 문제집
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |||
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| 19 | 20 | 21 | 22 | 23 | 24 | 25 |
| 26 | 27 | 28 | 29 | 30 | 31 |