

 2025년 1월1일 기준 관심가져보면 좋을 거 같은 VLM InternVL2.5
2025년 1월1일 기준 관심가져보면 좋을 거 같은 VLM InternVL2.5
프로젝트 페이지https://internvl.github.io/blog/2024-12-05-InternVL-2.5/ InternVL2.5We introduce InternVL 2.5, an advanced multimodal large language model (MLLM) series that builds upon InternVL 2.0, maintaining its core model architecture while introducing significant enhancements in training and testing strategies as well as data qualitinternvl.github.io 논문https://arxiv.org/pdf/2412.05271 허깅페이스https:/..
Why are Visually-Grounded Language Models Bad at Image Classification? Why are Visually-Grounded Language Models Bad at Image Classification?Image classification is one of the most fundamental capabilities of machine vision intelligence. In this work, we revisit the image classification task using visually-grounded language models (VLMs) such as GPT-4V and LLaVA. We find that existing proprietaa..
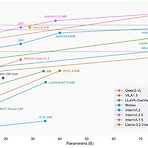
 2025년 VLM모델의 Vision Encoder 트렌드 예상(스케일링, Native Resolution Processing)
2025년 VLM모델의 Vision Encoder 트렌드 예상(스케일링, Native Resolution Processing)
2025년 VLM 모델 트렌드는 2개로 예상된다. 1. 스케일링 2. Native Resolution Processing 1. 스케일링 2024년도에 나온 VLM모델의 Vision Encoder 모델들의 사이즈는 대체로 300M~1B정도 였던 거 같다. Qwen2VL 도 Visual Encoder 로 675M 급의 ViT를 사용했고, 2B, 7B, 72B 모델이 있는데 다 Visual Enoder 는 같고 LLM Module만 크기를 냅다 키운식이다. 이런 전략은 LLaVA-NeXT에서도 쓰였다. https://llava-vl.github.io/blog/2024-01-30-llava-next/ LLaVA-NeXT: Improved reasoning, OCR, and world knowledgeLLaVA..
- Total
- Today
- Yesterday
- C++ Deploy
- 단축키
- 문제집
- MOT
- 조합
- LCA
- FairMOT
- 백준
- 파이참
- 가장 긴 증가하는 부분 수열
- cosine
- 순열
- 이분탐색
- 인공지능을 위한 선형대수
- 백준 11437
- 백준 11053
- 백트래킹
- 백준 1766
- Lowest Common Ancestor
- 위상 정렬 알고리즘
- 자료구조
- PyCharm
- ㅂ
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |||
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| 19 | 20 | 21 | 22 | 23 | 24 | 25 |
| 26 | 27 | 28 | 29 | 30 | 31 |