

onnxruntime inference 예제를 찾아보면 거의 input은 cpu에서 pre-processing한 numpy array(on cpu)를 session.run 함수의 입력으로 주는 경우가 많습니다. 그치만 실제로는 pre-processing도 GPU에서 하고 이걸 굳이 cpu 로 내려서 입력하는 일은 없는 게 일반적일겁니다. GPU, CPU 업로드, 다운로드 횟수는 줄일 수 있으면 최대한 줄여야 하는 아주 악의 축 같은 작업입니다. 특히 input 사이즈가 큰데 GPU 업로드 했다 CPU로 다운로드 했다 하다보면 차라리 CPU로 구현하는 것만 못한 속도가 나올겁니다. 그래서, GPU에 있는 데이터를 바로 추론할 수 있어야 합니다! onnxruntime 은 당연히 이런 기능을 제공하고 있습니다..
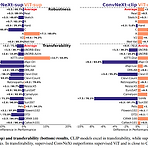 ConvNet vs ViT 비교 논문
ConvNet vs ViT 비교 논문
https://arxiv.org/abs/2311.09215 ConvNet vs Transformer, Supervised vs CLIP: Beyond ImageNet Accuracy Modern computer vision offers a great variety of models to practitioners, and selecting a model from multiple options for specific applications can be challenging. Conventionally, competing model architectures and training protocols are compared by their c arxiv.org 대충 결론만 봄 나중에 다시 읽어보자(과연?)
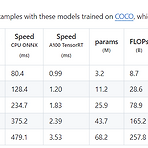
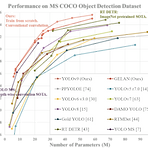 20240222 YOLOv9 가 공개되다.
20240222 YOLOv9 가 공개되다.
https://github.com/WongKinYiu/yolov9 GitHub - WongKinYiu/yolov9: Implementation of paper - YOLOv9: Learning What You Want to Learn Using Programmable Gradient Inform Implementation of paper - YOLOv9: Learning What You Want to Learn Using Programmable Gradient Information - WongKinYiu/yolov9 github.com https://arxiv.org/pdf/2402.13616.pdf X축이 Latency 면 어떻게 그려질지 궁금하다.
 META V-JEPA
META V-JEPA
https://ai.meta.com/blog/v-jepa-yann-lecun-ai-model-video-joint-embedding-predictive-architecture/ V-JEPA: The next step toward advanced machine intelligence Previous work had to do full fine-tuning, which means that after pre-training your model, when you want the model to get really good at fine-grained action recognition while you’re adapting your model to take on that task, you have to updat..
 Google Magika 파일 종류 인식을 AI로
Google Magika 파일 종류 인식을 AI로
https://opensource.googleblog.com/2024/02/magika-ai-powered-fast-and-efficient-file-type-identification.html Magika: AI powered fast and efficient file type identification Magika code and model are freely available starting today in Github under the Apache2 License. opensource.googleblog.com https://github.com/google/magika GitHub - google/magika: Detect file content types with deep learning Det..
 COCO pre-trained YOLOv5, YOLOv8의 입력 이미지 사이즈와 COCO 데이터셋의 이미지 해상도
COCO pre-trained YOLOv5, YOLOv8의 입력 이미지 사이즈와 COCO 데이터셋의 이미지 해상도
COCO pre-trained YOLOv5, 8의 입력 이미지 사이즈는 대개 640x640으로 알려져있습니다. YOLOv5는 1280x1280 사이즈를 입력으로 받는 High mAP 지향형 모델도 있기는 합니다. 왜 640x640일까요? 우선 FPN 구조이자 입력 이미지가 모델 구조에 의해 32x Downsampling이 되기 때문에 입력 이미지의 해상도가 32의 배수여야 하는 제한이 있습니다. 그러고보면 640이 32의 배수인 걸 알 수 있습니다. 근데 32의 배수는 무수히 많은데 왜 640 일까요? COCO 데이터셋의 해상도에 대한 통계치를 추출해보겠습니다. 2017년도에 구축된 데이터셋 기준입니다. Train #images: 118287 min h: 51, max h: 640, mean h: 484..

 YOLOv8 low-level output visualization code
YOLOv8 low-level output visualization code
https://github.com/developer0hye/Explainable-YOLOv8 GitHub - developer0hye/Explainable-YOLOv8: Visualize the low-level outputs of YOLOv8 to analyze and understand the areas where o Visualize the low-level outputs of YOLOv8 to analyze and understand the areas where our model focuses. Specifically, illustrate which anchor points are activated to predict bounding boxes. - GitHub... github.com 어떤 앵커..
https://machinelearning.apple.com/research/neural-engine-transformers Deploying Transformers on the Apple Neural Engine An increasing number of the machine learning (ML) models we build at Apple each year are either partly or fully adopting the [Transformer… machinelearning.apple.com https://machinelearning.apple.com/research/vision-transformers Deploying Attention-Based Vision Transformers to A..
 [Deep Learning] 관심이 생긴 Detection 모델 Plain-DETR, DETR Does Not Need Multi-Scale or Locality Design
[Deep Learning] 관심이 생긴 Detection 모델 Plain-DETR, DETR Does Not Need Multi-Scale or Locality Design
https://github.com/impiga/Plain-DETR GitHub - impiga/Plain-DETR: [ICCV2023] DETR Doesn’t Need Multi-Scale or Locality Design [ICCV2023] DETR Doesn’t Need Multi-Scale or Locality Design - GitHub - impiga/Plain-DETR: [ICCV2023] DETR Doesn’t Need Multi-Scale or Locality Design github.com https://openaccess.thecvf.com/content/ICCV2023/html/Lin_DETR_Does_Not_Need_Multi-Scale_or_Locality_Design_ICCV_2..
- Total
- Today
- Yesterday
- 백준 11437
- 백준 11053
- 가장 긴 증가하는 부분 수열
- 문제집
- ㅂ
- PyCharm
- 조합
- 백트래킹
- MOT
- 파이참
- 위상 정렬 알고리즘
- 백준
- 자료구조
- 순열
- 단축키
- 이분탐색
- Lowest Common Ancestor
- FairMOT
- LCA
- 백준 1766
- cosine
- C++ Deploy
- 인공지능을 위한 선형대수
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |