

 Exploring Plain Vision Transformer Backbones for Object Detection 리뷰
Exploring Plain Vision Transformer Backbones for Object Detection 리뷰
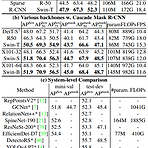
https://arxiv.org/abs/2203.16527 Exploring Plain Vision Transformer Backbones for Object Detection We explore the plain, non-hierarchical Vision Transformer (ViT) as a backbone network for object detection. This design enables the original ViT architecture to be fine-tuned for object detection without needing to redesign a hierarchical backbone for pre- arxiv.org 배경 Abstract에서 첫 문장으로 We explore ..
https://github.com/xingyizhou/CenterNet/blob/master/src/lib/opts.py GitHub - xingyizhou/CenterNet: Object detection, 3D detection, and pose estimation using center point detection: Object detection, 3D detection, and pose estimation using center point detection: - GitHub - xingyizhou/CenterNet: Object detection, 3D detection, and pose estimation using center point detection: github.com
https://github.com/ZJULearning/ttfnet/blob/700ad90c50786c8c16c4efa35c60baa907a07461/mmdet/models/anchor_heads/ttf_head.py#L334-L365 GitHub - ZJULearning/ttfnet Contribute to ZJULearning/ttfnet development by creating an account on GitHub. github.com
PyTorch에서 제공하는 AutoMixedPrecision 기능을 활용하여 모델을 학습하다 보면 학습이 잘 안되는 경우가 발생한다. 구글링을 해보면 이런 경우를 심심치 않게 찾아볼 수 있다. https://github.com/pytorch/pytorch/issues/40497 Mixed precision causes NaN loss · Issue #40497 · pytorch/pytorch 🐛 Bug I'm using autocast with GradScaler to train on mixed precision. For small dataset, it works fine. But when I trained on bigger dataset, after few epochs (3-4), the loss tu..
https://github.com/pytorch/pytorch/blob/46a88036afacad5aee5ba2640d6055051bb879a1/aten/src/ATen/native/Normalization.cpp#L189-L192 GitHub - pytorch/pytorch: Tensors and Dynamic neural networks in Python with strong GPU acceleration Tensors and Dynamic neural networks in Python with strong GPU acceleration - GitHub - pytorch/pytorch: Tensors and Dynamic neural networks in Python with strong GPU ac..
https://notmatthancock.github.io/2017/03/23/simple-batch-stat-updates.html Batch updates for simple statistics It’s typical in many optimization problems in data analysis to standardize your data by subtracting off the empirical mean and dividing by the empirical standard deviation. However, in “online” situations where the data is acquired one at a time or i notmatthancock.github.io
https://github.com/ptrblck/pytorch_misc/blob/31ac50c415f16cf7fec277dbdba72b9fb4d732d3/batch_norm_manual.py#L39 GitHub - ptrblck/pytorch_misc: Code snippets created for the PyTorch discussion board Code snippets created for the PyTorch discussion board - GitHub - ptrblck/pytorch_misc: Code snippets created for the PyTorch discussion board github.com
https://github.com/zhenghao977/FCOS-PyTorch-37.2AP/blob/2bfa4b6ca57358f52f7bc7b44f506608e99894e6/model/fcos.py#L22-L35 GitHub - zhenghao977/FCOS-PyTorch-37.2AP: A pure torch implement of FCOS 37.2AP A pure torch implement of FCOS 37.2AP. Contribute to zhenghao977/FCOS-PyTorch-37.2AP development by creating an account on GitHub. github.com def freeze_bn(module): if isinstance(module,nn.BatchNorm2..
 [딥 러닝, Object Detection] Adaptive Training Sample Selection
[딥 러닝, Object Detection] Adaptive Training Sample Selection
https://velog.io/@markany/%EB%94%A5-%EB%9F%AC%EB%8B%9D-Object-Detection-Adaptive-Training-Sample-Selection [딥 러닝, Object Detection] ATSS: Adaptive Training Sample Selection 본 포스트에서 리뷰할 논문의 제목은 Bridging the Gap Between Anchor-based and Anchor-free Detection via Adaptive Training Sample Selection 입니다.한국어로 표현하기 모호한 부분은 논문에서 velog.io 회사 블로그에 정리
https://github.com/developer0hye/Torch-Warmup GitHub - developer0hye/Torch-Warmup: Easiest way to use learning rate warmup method on PyTorch Easiest way to use learning rate warmup method on PyTorch - GitHub - developer0hye/Torch-Warmup: Easiest way to use learning rate warmup method on PyTorch github.com 이 프로젝트를 참고하면 된다.
- Total
- Today
- Yesterday
- 백준 11053
- cosine
- 백트래킹
- MOT
- FairMOT
- C++ Deploy
- 문제집
- 인공지능을 위한 선형대수
- 순열
- 가장 긴 증가하는 부분 수열
- Lowest Common Ancestor
- PyCharm
- 자료구조
- 백준
- 조합
- 백준 1766
- 이분탐색
- 파이참
- 백준 11437
- 단축키
- 위상 정렬 알고리즘
- LCA
- ㅂ
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |||
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| 19 | 20 | 21 | 22 | 23 | 24 | 25 |
| 26 | 27 | 28 | 29 | 30 | 31 |