
티스토리 뷰
[Deep Learning] C++ ONNXRuntime 1.15.1 official release 라이브러리 기준 TensorRT dynamic batch inference 방법
developer0hye 2023. 7. 25. 21:27https://onnxruntime.ai/docs/execution-providers/TensorRT-ExecutionProvider.html#c-api-example
NVIDIA - TensorRT
Instructions to execute ONNX Runtime on NVIDIA GPUs with the TensorRT execution provider
onnxruntime.ai

20230725 기준 ONNXRuntime Official Docs 에 안내된 TensorRT 사용법으로는 TensorRT를 완전히 활용할 수 없는 걸로 파악된다.
여기서 완전히 활용 못한다는 의미는 Dynamic Batch 사이즈를 갖는 데이터에 대한 Inference 를 의미한다. 왜냐! 처음에 모델 Build할때 min, opt, max shape을 지정해줘야 하는데 OrtTensorRTProviderOptions 에는 이 옵션이 없다... 그래서, 모델은 Dynamic Batch 데이터를 처리하도록 어찌저찌 빌드는 되는데, Dynamic Shape Data를 처리하다보면 중간중간 Build를 다시 해버린다. 내 경우에는 Build 시간이 9분이 채 넘어가는 경우도 흔했다. Optimization Level 을 조정한다거나 다른 파라미터를 수정하여 Build 시간 자체를 줄이는 방법도 있겠지만 모델 Build 하는 동안 처리할 데이터 큐는 점점 쌓이다 못해 초과할 것이고 데이터들은 드랍될 것이다.
Issue/PR 을 찾아보니 다행히 관련 PR이 있었고 Merge까지 돼있었다!
https://github.com/microsoft/onnxruntime/pull/15546
Support explicit TRT profiles from provider options by chilo-ms · Pull Request #15546 · microsoft/onnxruntime
Previous behavior of TRT EP to set TRT optimization profiles for dynamic shape input is based on input tensor values. Users can't explicitly specify the profiles. This PR makes users capable of spe...
github.com

위 PR을 확인한뒤에 onnxruntime/include/onnxruntime/core/providers/tensorrt/tensorrt_provider_options.h 를 확인해보니,
OrtTensorRTProviderOptionsV2 에는 선언이 돼있는 걸 확인할 수 있었다.

이를 따라서 Session을 생성하기 위한 코드가 구현된 파일에 내가 직접 선언했다. 직접 정의 안하고 저 Struct 가 알아서 잘 include 되어서 호출될줄 알고 내가 객체를 생성(OrtTensorRTProviderOptionsV2 tensorrt_options;)하려니 에러가 떴었다...
사실 저 v2 주석에 아래와 같이 작성돼있다.
유저는 CreateTensorRTProviderOptions 를 사용해야만 OrtTensorRTProviderOptionsV2 객체를 다룰 수 있다는데, CreateTensorRTProviderOptions 가 사용된 test 코드 참고해서 해보려니까 빌드가 제대로 안됐다... 그래서 그냥 내가 직접 선언을 한 것이다.
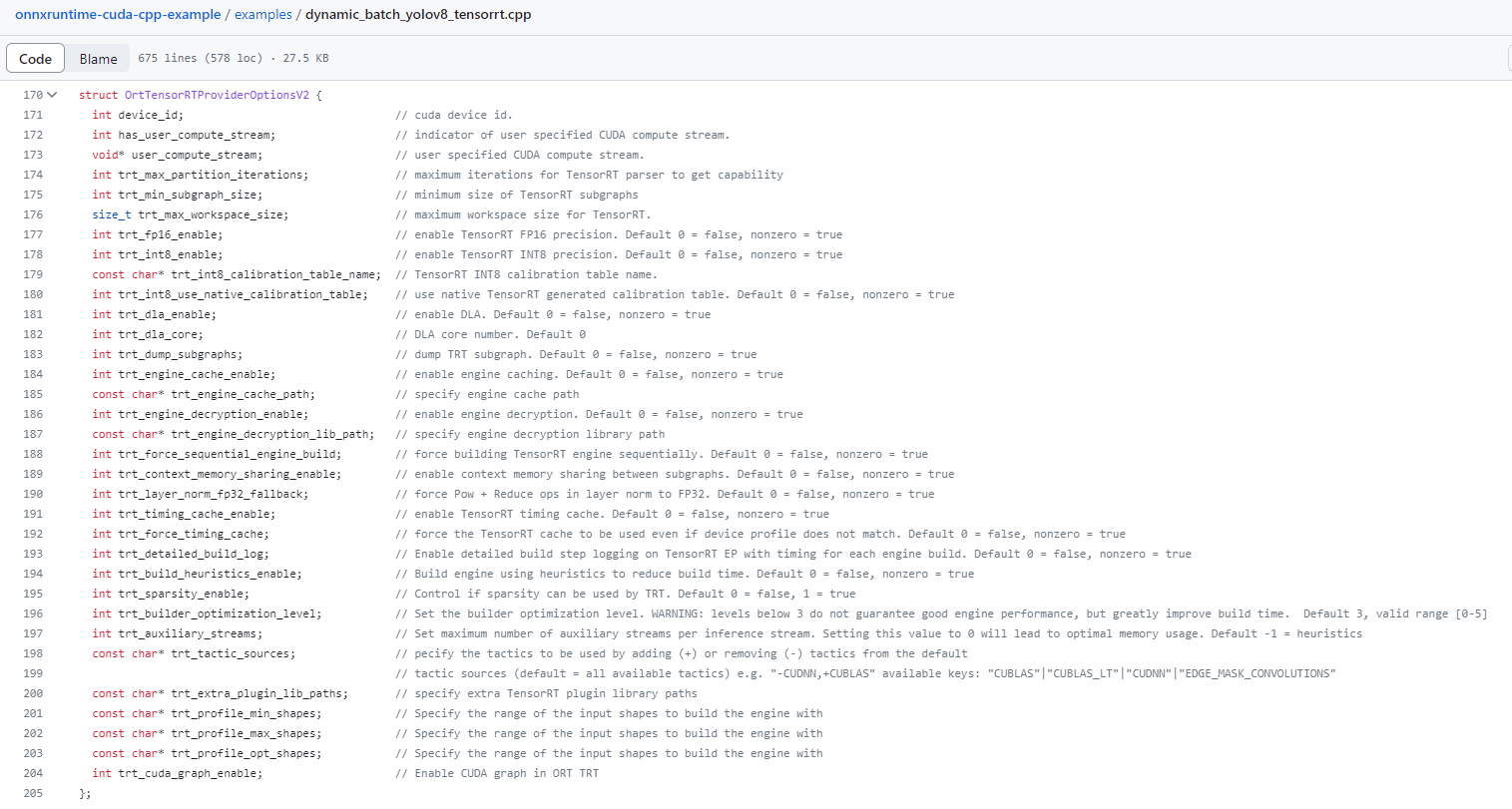
struct OrtTensorRTProviderOptionsV2 {
int device_id; // cuda device id.
int has_user_compute_stream; // indicator of user specified CUDA compute stream.
void* user_compute_stream; // user specified CUDA compute stream.
int trt_max_partition_iterations; // maximum iterations for TensorRT parser to get capability
int trt_min_subgraph_size; // minimum size of TensorRT subgraphs
size_t trt_max_workspace_size; // maximum workspace size for TensorRT.
int trt_fp16_enable; // enable TensorRT FP16 precision. Default 0 = false, nonzero = true
int trt_int8_enable; // enable TensorRT INT8 precision. Default 0 = false, nonzero = true
const char* trt_int8_calibration_table_name; // TensorRT INT8 calibration table name.
int trt_int8_use_native_calibration_table; // use native TensorRT generated calibration table. Default 0 = false, nonzero = true
int trt_dla_enable; // enable DLA. Default 0 = false, nonzero = true
int trt_dla_core; // DLA core number. Default 0
int trt_dump_subgraphs; // dump TRT subgraph. Default 0 = false, nonzero = true
int trt_engine_cache_enable; // enable engine caching. Default 0 = false, nonzero = true
const char* trt_engine_cache_path; // specify engine cache path
int trt_engine_decryption_enable; // enable engine decryption. Default 0 = false, nonzero = true
const char* trt_engine_decryption_lib_path; // specify engine decryption library path
int trt_force_sequential_engine_build; // force building TensorRT engine sequentially. Default 0 = false, nonzero = true
int trt_context_memory_sharing_enable; // enable context memory sharing between subgraphs. Default 0 = false, nonzero = true
int trt_layer_norm_fp32_fallback; // force Pow + Reduce ops in layer norm to FP32. Default 0 = false, nonzero = true
int trt_timing_cache_enable; // enable TensorRT timing cache. Default 0 = false, nonzero = true
int trt_force_timing_cache; // force the TensorRT cache to be used even if device profile does not match. Default 0 = false, nonzero = true
int trt_detailed_build_log; // Enable detailed build step logging on TensorRT EP with timing for each engine build. Default 0 = false, nonzero = true
int trt_build_heuristics_enable; // Build engine using heuristics to reduce build time. Default 0 = false, nonzero = true
int trt_sparsity_enable; // Control if sparsity can be used by TRT. Default 0 = false, 1 = true
int trt_builder_optimization_level; // Set the builder optimization level. WARNING: levels below 3 do not guarantee good engine performance, but greatly improve build time. Default 3, valid range [0-5]
int trt_auxiliary_streams; // Set maximum number of auxiliary streams per inference stream. Setting this value to 0 will lead to optimal memory usage. Default -1 = heuristics
const char* trt_tactic_sources; // pecify the tactics to be used by adding (+) or removing (-) tactics from the default
// tactic sources (default = all available tactics) e.g. "-CUDNN,+CUBLAS" available keys: "CUBLAS"|"CUBLAS_LT"|"CUDNN"|"EDGE_MASK_CONVOLUTIONS"
const char* trt_extra_plugin_lib_paths; // specify extra TensorRT plugin library paths
const char* trt_profile_min_shapes; // Specify the range of the input shapes to build the engine with
const char* trt_profile_max_shapes; // Specify the range of the input shapes to build the engine with
const char* trt_profile_opt_shapes; // Specify the range of the input shapes to build the engine with
int trt_cuda_graph_enable; // Enable CUDA graph in ORT TRT
};
이후 ONNXRuntime 테스트 코드에 작성된 코드를 따라서

필요한 값들을 내 케이스에 맞게 세팅했다.(trt_fp16_enable, trt_profile_*_shapes),
trt_profile_*_shapes 에 "images:~" 인 건 onnx 모델 생성할때 input 이름을 "images"로 해서 그렇다

int device_id = gpu_id;
int trt_max_partition_iterations = 1000;
int trt_min_subgraph_size = 1;
size_t trt_max_workspace_size = 1 << 30;
bool trt_fp16_enable = true;
bool trt_int8_enable = false;
std::string trt_int8_calibration_table_name = "";
bool trt_int8_use_native_calibration_table = false;
bool trt_dla_enable = false;
int trt_dla_core = 0;
bool trt_dump_subgraphs = false;
bool trt_engine_cache_enable = false;
std::string trt_engine_cache_path = "";
bool trt_engine_decryption_enable = false;
std::string trt_engine_decryption_lib_path = "";
bool trt_force_sequential_engine_build = false;
bool trt_context_memory_sharing_enable = false;
bool trt_layer_norm_fp32_fallback = false;
bool trt_timing_cache_enable = false;
bool trt_force_timing_cache = false;
bool trt_detailed_build_log = false;
bool trt_build_heuristics_enable = false;
bool trt_sparsity_enable = false;
int trt_builder_optimization_level = 3;
int trt_auxiliary_streams = -1;
std::string trt_tactic_sources = "";
std::string trt_extra_plugin_lib_paths = "";
std::string trt_profile_min_shapes = "images:1x3x640x640";
std::string trt_profile_max_shapes = "images:64x3x640x640";
std::string trt_profile_opt_shapes = "images:8x3x640x640";
bool trt_cuda_graph_enable = false;
OrtTensorRTProviderOptionsV2 tensorrt_options;
tensorrt_options.device_id = device_id;
tensorrt_options.has_user_compute_stream = 0;
tensorrt_options.user_compute_stream = nullptr;
tensorrt_options.trt_max_partition_iterations = trt_max_partition_iterations;
tensorrt_options.trt_min_subgraph_size = trt_min_subgraph_size;
tensorrt_options.trt_max_workspace_size = trt_max_workspace_size;
tensorrt_options.trt_fp16_enable = trt_fp16_enable;
tensorrt_options.trt_int8_enable = trt_int8_enable;
tensorrt_options.trt_int8_calibration_table_name = trt_int8_calibration_table_name.c_str();
tensorrt_options.trt_int8_use_native_calibration_table = trt_int8_use_native_calibration_table;
tensorrt_options.trt_dla_enable = trt_dla_enable;
tensorrt_options.trt_dla_core = trt_dla_core;
tensorrt_options.trt_dump_subgraphs = trt_dump_subgraphs;
tensorrt_options.trt_engine_cache_enable = trt_engine_cache_enable;
tensorrt_options.trt_engine_cache_path = trt_engine_cache_path.c_str();
tensorrt_options.trt_engine_decryption_enable = trt_engine_decryption_enable;
tensorrt_options.trt_engine_decryption_lib_path = trt_engine_decryption_lib_path.c_str();
tensorrt_options.trt_force_sequential_engine_build = trt_force_sequential_engine_build;
tensorrt_options.trt_context_memory_sharing_enable = trt_context_memory_sharing_enable;
tensorrt_options.trt_layer_norm_fp32_fallback = trt_layer_norm_fp32_fallback;
tensorrt_options.trt_timing_cache_enable = trt_timing_cache_enable;
tensorrt_options.trt_force_timing_cache = trt_force_timing_cache;
tensorrt_options.trt_detailed_build_log = trt_detailed_build_log;
tensorrt_options.trt_build_heuristics_enable = trt_build_heuristics_enable;
tensorrt_options.trt_sparsity_enable = trt_sparsity_enable;
tensorrt_options.trt_builder_optimization_level = trt_builder_optimization_level;
tensorrt_options.trt_auxiliary_streams = trt_auxiliary_streams;
tensorrt_options.trt_tactic_sources = trt_tactic_sources.c_str();
tensorrt_options.trt_extra_plugin_lib_paths = trt_extra_plugin_lib_paths.c_str();
tensorrt_options.trt_profile_min_shapes = trt_profile_min_shapes.c_str();
tensorrt_options.trt_profile_max_shapes = trt_profile_max_shapes.c_str();
tensorrt_options.trt_profile_opt_shapes = trt_profile_opt_shapes.c_str();
tensorrt_options.trt_cuda_graph_enable = trt_cuda_graph_enable;
session_options.AppendExecutionProvider_TensorRT_V2(tensorrt_options);
min_shapes, max_shapes, opt_shapes를 지정한 것을 확인할 수 있다!
이렇게 하면, Ort::Session 생성자를 호출할때 빌드를 한 번하고 그 이후에는 따로 빌드하지 않는다.
전체 코드는 아래 소스코드 파일에서 확인 가능하다.
'Deep Learning' 카테고리의 다른 글
| [Deep Learning] 2D Human Pose Estimation을 한 줄로! onepose (2) | 2023.10.05 |
|---|---|
| [Deep Learning] Pose Estimation 데이터셋별 annotation 예시 (0) | 2023.09.30 |
| [ONNXRuntime] ONNX 모델 CPU, GPU 결과 차이 기록 (0) | 2023.07.18 |
| [Deep Learning] C++ ONNXRuntime model metadata 읽기 (0) | 2023.07.17 |
| [Deep Learning] ONNXRuntime Output이 계속 변한다면... (0) | 2023.07.03 |
- Total
- Today
- Yesterday
- 이분탐색
- cosine
- C++ Deploy
- LCA
- 조합
- 문제집
- 순열
- FairMOT
- Lowest Common Ancestor
- 파이참
- 위상 정렬 알고리즘
- ㅂ
- 백준 11053
- 백준 11437
- 백준 1766
- 인공지능을 위한 선형대수
- MOT
- PyCharm
- 백준
- 가장 긴 증가하는 부분 수열
- 백트래킹
- 자료구조
- 단축키
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |||
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| 19 | 20 | 21 | 22 | 23 | 24 | 25 |
| 26 | 27 | 28 | 29 | 30 | 31 |