

티스토리 뷰
[딥 러닝, Object Detection] IoU-aware Single-stage Object Detector for Accurate Localization 논문 리뷰
developer0hye 2022. 2. 3. 20:56IoU-aware single-stage object detector for accurate localization
Single-stage object detectors have been widely applied in many computer vision applications due to their simpleness and high efficiency. However, the …
www.sciencedirect.com
Single-stage object detectors(YOLO Series, Centernet 등)는 Classification score와 Localization accuracy 간에 낮은 Correlation을 보인다. 그리고, 이는 디텍션 모델의 성능을 저하시키는 원인이 된다.

위 그림을 보면 모델이 예측한 6개의 바운딩 박스(A1, A2, B1, B2, C1, C2)가 있다. 위 바운딩 박스들을 보면 Localization이 잘된 박스는 A1, B1, C1 이다. 그런데, 위 바운딩 박스들은 Class score 기반의 NMS(Non-maximum suppression)를 거치면 Localization accuracy가 낮지만 Class score(=S)가 높은 A2, B2, C2 박스가 최종적으로 남고 A1, B1, C1 박스는 제거된다. 이 박스들로 AP(Average Precision)을 측정하면 TP와 FP를 판가름하는 IoU Threshold 값이 높아질수록 Detector의 성능은 낮게 나올 것이다.
논문에서는 위와 같은 Class scroe와 Localization accuracy 간의 낮은 Correlation의 원인을 Classification을 위한 Loss와 Localization을 위한 Loss가 Independent objective functions(=Loss fucntion)에 의해 계산되어서 그렇다고 주장한다.
이 논문에서는 위 문제를 해결하고자 바운딩 박스의 Localization accuracy(=IoU, Intersection of Union)를 예측하는 방법을 제안한다.
Localization accuracy를 예측한다니! 당연히 모델에 변화가 있을 수 밖에 없다.

위 그림에서 IoU Prediction 헤드를 제외하고는 기존에 제안되어온 여타 FPN(Feature pyramid network)기반 Object Detectors와 모델 구조가 크게 다른 부분이 없다. 저 IoU Prediction 헤드가 바로 Localization accuracy를 예측하기 위한 헤드이다. 참고로 RetinaNet을 베이스로하여 저 IoU Prediction 헤드를 추가했다고 한다.
모델의 efficiency를 keep하기 위하여 Regression Branch에 3x3 Convolution layer만 딱 하나 추가하고 IoU를 예측하도록 설계하였다.
이 IoU Prediction 헤드를 학습시키기 위해 사용한 Loss는 BCE(Binary cross-entropy loss)를 사용했다. Ground Truth는 학습과정에서 예측한 바운딩박스와 이 바운딩박스의 Ground Truth 대상이되는 바운딩박스간의 IoU이다.

\(N_{Pos}\) 는 Positive sample의 수(=이미지내 Ground Truth 수)이다. (3)은 앞서 말한 IoU Loss이다. (4)는 예측한 바운딩박스와 이 바운딩 박스의 Ground Truth 대상이되는 바운딩 박스간 IoU이다. (5)는 (4)로 미분했을때의 Gradient이다. 이걸 계산해서 모델을 학습시키면 모델의 Localization 성능이 향상되도록 학습이된다는데... 잘 이해가 안됐다. 논문의 3.2 Training 절에서 해당 내용이 작성되어 있는데 잘이해를하지 못했다 ㅜㅜ. 뒤에서 작성하겠지만 Table 4.를 보면 이 Gradient를 계산하여 모델을 학습시켰을때와 그렇지 않을때의 결과를 확인할 수 있다. 마지막으로, 식(6)는 IoU-aware obejct detector를 학습시키기 위한 Loss이다.
Inference 단계에서 어떻게 썼는지 체크하는 게 중요하다.
그냥 Class score x Predicted IoU 로 최종적인 Confidence score를 계산한줄 알았는데 오산이였다!

식은 위와 같다. \(p_{i}\) 가 Class score, \(IoU_{i}\)가 Predicted IoU이다. 저 \(\alpha\)는 [0, 1] 범위를 갖는 Hyper parameter이다. \(\alpha\)가 1이면 Class score만 보겠다는 얘기고, 0이면 IoU(=Localizaion accuracy)만 보겠다는 얘기다. 나라면 그냥 \(S_{det}=p_{i}IoU_{i}\) 해놓고 성능 안나왔으면 아 이거 안되네~ 했을 거 같다... Hyper parameter가 늘어나는 게 좋은 선택지는 아닐 수 있지만...
실험파트이다.

RetinaNet* - Backbone 이랑 IoU-aware RetinaNet - Backbone이랑 짝 맞는 거 끼리 비교해보면 된다. AP가 증가되는 것을 확인할 수 있다.

Table 2는 IoU Prediction 헤드를 학습시킬때 Loss에 따른 AP를 기록한 표이다. BCE를 썼을때 L2 loss보다 높은 AP를 기록하였다.

Table 3은 Inference 단계에서 최종적으로 Confidence score를 계산할때 \(\alpha\) 값에 따른 AP를 기록한 표이다. none은 Confidence score를 \(S_{det}=p_{i}IoU_{i}\)로 계산했을때의 결과이다. 이 결과만 보면 굳이 \(\alpha\)를 힘들게 찾을 필요는 없어보인다. 근데 결과를 보면 \(\alpha\)를 0.3 으로 낮게 낮췄을때, 즉 Class score 보다 Localization accuracy에 초점을 맞췄을때도 AP가 그리 저하되지 않는 것을 확인할 수 있다.

Table 4는 IoU Loss를 \(\hat{IoU_{i}}\) 으로 미분한 Gradient를 계산하여 모델을 학습시켰을때, \(\alpha\) 값에 따른 AP를 기록한 표이다. Table 3는 IoU Loss를 \(\hat{IoU_{i}}\) 으로 미분한 Gradient를 계산하지 않고 모델을 학습시켰을때의 결과이다. Table 3과 Table 4를 비교해보면 Table 4의 AP가 대체로 높은 것을 확인할 수 있다.
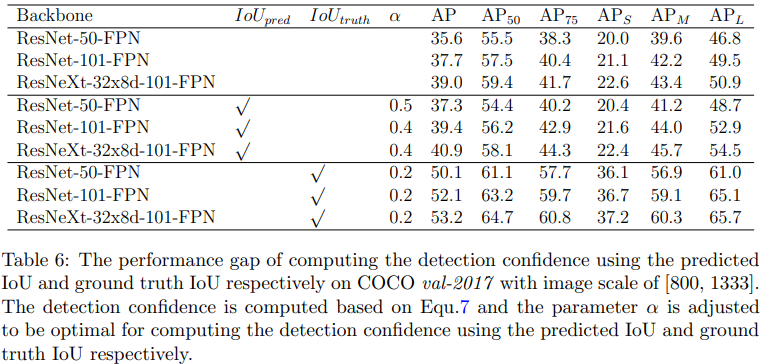
Table 6는 예측한 IoU대신에 실제 Ground Truth 박스간 IoU(=\(IoU_{truth}\))를 사용하여 Confidence Score를 사용했을때의 결과이다. IoU가 정말로 잘 예측이 된다면 성능이 어마어마하게 올라갈 수 있다는 것을 의미하며, 한편으로는 예측된 IoU의 정확도가 크게 낮다는 것으로도 해석할 수 있다. 여기서, \(IoU_{truth}\) 는 예측한 박스와 가장 높은 IoU를 갖는 Ground Truth 박스간 IoU를 의미한다. 원래 AP 측정할때 True Postive로 판단되려면 IoU가 특정 쓰레스홀드보다 높으면서 클래스도 일치해야하는데 \(IoU_{truth}\)는 클래스를 고려하지 않고 측정된 값이다.
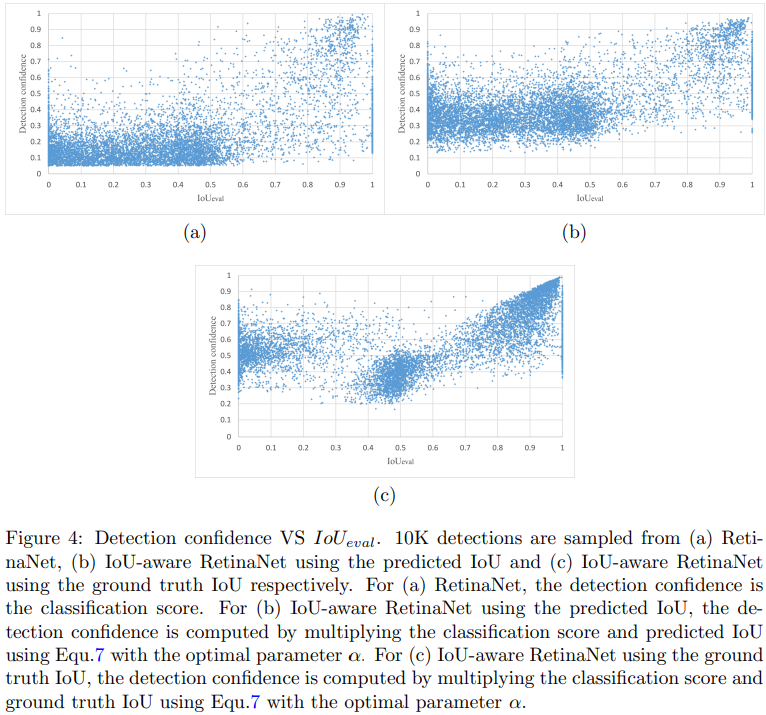
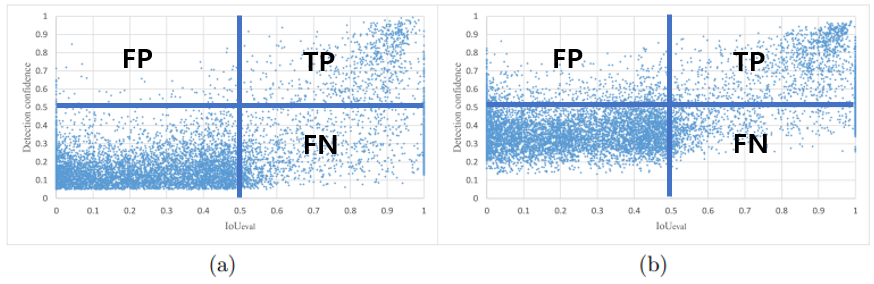
위 그림은 예측한 바운딩 박스 10,000개를 샘플링하고 이 박스들과 Ground Truth 박스대비 \(IoU_{eval}\) 대비 Detection confidence를 산점도(Scatter plot)로 나타낸 그림이다. 여기서, 여기서, \(IoU_{eval}\) 은 예측한 박스와 클래스가 일치하면서 가장 높은 IoU를 갖는 Ground Truth 박스간 IoU를 의미한다. \(IoU_{truth}\)와 차이를 이해하는 것이 중요하다. 잘 이해가 안된다면 논문의 Fig 5. 를 보면 된다. (a), (b), (c)는 Class score로 Detection confidence를 매겼을때의 결과이고, (b)는 Predicted localization accuracy도 추가적으로 이용했을때의 결과, (c)는 Ground truth localization accuracy를 이용했을때의 결과이다. 이상적인 결과는 \(IoU_{eval}\)과 Detection confidence가 선형적인 관계를 이루는 것이라고 생각된다. 이러한 관점에서 그림 (a)와 (b)를 보았을때, Localization accuracy를 Detection confidence에 반영해주었을때... 어떻게 좋게 잘 해석이 안된다. 대체로 Detection confidence가 상승한 점이 명확히 보인다. 실제로 배포시에는 특정 Detection confidence threshold를 정의하고 이보다 낮은 박스들을 무시한다. 대개 이 값을 0.5로 설정하고 TP, FP여부에 대한 판단을 위한 IoU Threshold를 0.5로 정의한다고 했을때, 그래프를 사분면으로 나누어 포인트들의 FP, TP, FN 여부를 아래 처럼 분류할 수 있을 거 같다. 흠... 이렇게만 보면 제안하는 방법을 사용했을때 Detection confidence에 대한 튜닝없이는 오히려 FP수가 증가된 것으로 해석된다.
'Deep Learning' 카테고리의 다른 글
| [딥 러닝, Object Detection] Adaptive Training Sample Selection (0) | 2022.03.02 |
|---|---|
| [PyTorch] Learning Rate Warmup 가장 쉽게 쓰는 방법 (0) | 2022.02.14 |
| [딥 러닝, Object Detection] Gaussian YOLOv3 논문 리뷰 (0) | 2022.01.31 |
| 칼만 필터(Kalman Filter)는 과연 SORT 트래킹 알고리즘에 필요할까 (10) | 2021.12.27 |
| [논문] ByteTrack 리뷰 (8) | 2021.12.23 |
- Total
- Today
- Yesterday
- 백준 11437
- 순열
- Lowest Common Ancestor
- 파이참
- 가장 긴 증가하는 부분 수열
- 위상 정렬 알고리즘
- 자료구조
- PyCharm
- 조합
- MOT
- LCA
- C++ Deploy
- FairMOT
- ㅂ
- 문제집
- 백준 1766
- 단축키
- 백준
- 인공지능을 위한 선형대수
- 백준 11053
- 이분탐색
- cosine
- 백트래킹
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |||
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| 19 | 20 | 21 | 22 | 23 | 24 | 25 |
| 26 | 27 | 28 | 29 | 30 | 31 |