
티스토리 뷰
깔짝 깔짝 LLM, VLM 에 관심을 기웃 기웃 거려보고 있습니다.
아직 잘 모르고 예제 코드만 돌려본 정도 입니다.
먼저 Llama3 8B 모델의 경우 모델 웨이트 업로드에만 15~16GB 가 소요됐었습니다. 이러면... 집에서 3070 8GB GPU로 이것 저것 뭔가 해보려는 저는 할 수가 없습니다. 모델 일부만 GPU에 업로드 한다거나? 하는 방식이 있지 않을까 싶은데 아직 찾아보지는 않았습니다.
보니까 llm 모델들은 대체로 4bit quantization 모델도 같이 공개가 되는 경우가 많더라고요!
이중에는 서울과학기술대학교 주도로 학습되고 공개된 웨이트가 존재하였습니다.
https://huggingface.co/MLP-KTLim/llama-3-Korean-Bllossom-8B-gguf-Q4_K_M
MLP-KTLim/llama-3-Korean-Bllossom-8B-gguf-Q4_K_M · Hugging Face
Update! [2024.06.18] 사전학습량을 250GB까지 늘린 Bllossom ELO모델로 업데이트 되었습니다. 다만 단어확장은 하지 않았습니다. 기존 단어확장된 long-context 모델을 활용하고 싶으신분은 개인연락주세요!
huggingface.co

돌려보고 싶었습니다.
돌려보았습니다.
https://github.com/developer0hye/llama-3-korean-bllossom-8b-q4-docker
GitHub - developer0hye/llama-3-korean-bllossom-8b-q4-docker: 8GB GPU로 8B 모델 추론을 추구하면 안되는걸까
8GB GPU로 8B 모델 추론을 추구하면 안되는걸까. Contribute to developer0hye/llama-3-korean-bllossom-8b-q4-docker development by creating an account on GitHub.
github.com
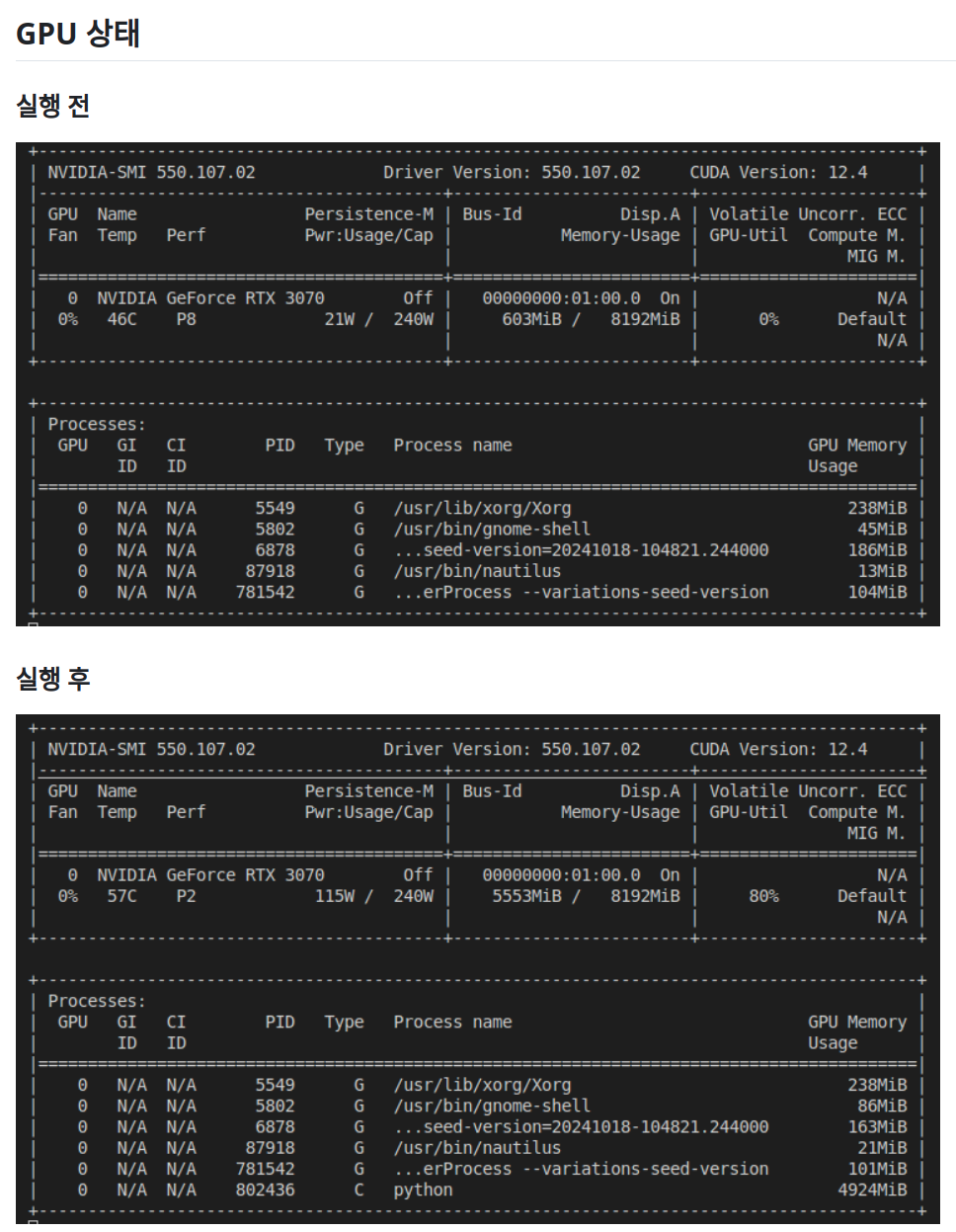
예제는 돌아갔습니다. 얏호!
다른 모델들도 4bit quantization 모델로 돌려보려고 합니다.
걱정 - Quantization 에 의한 성능 손실은 없을까?
https://huggingface.co/Qwen/Qwen2-VL-72B-Instruct-GPTQ-Int4
Qwen/Qwen2-VL-72B-Instruct-GPTQ-Int4 · Hugging Face
Qwen2-VL-72B-Instruct-GPTQ-Int4 Introduction We're excited to unveil Qwen2-VL, the latest iteration of our Qwen-VL model, representing nearly a year of innovation. What’s New in Qwen2-VL? Key Enhancements: SoTA understanding of images of various resoluti
huggingface.co

LLM 은 아니고 VLM 찾다가 본 퀀타이제이션 방법별 성능 테이블을 찾았습니다. Quantization 한 경우 오히려 성능이 소폭 상승한 경우도 보입니다만, 기보유한 데이터셋에 직접 테스트를 해보는 게 좋을 거 같네요!

참고로 Qwen2-VL-72B-Instruct 모델의 경우에는 Quantization 방식 및 Input Length에 따라서 위와 같은 추론 속도와 메모리 사용량을 보인다고 합니다.
'Deep Learning' 카테고리의 다른 글
| GOT OCR 2.0은 한국어 OCR이 가능한가? (0) | 2024.10.26 |
|---|---|
| LLM 한국어 이해 성능 파악하기 좋은 벤치마크, 리더보드, article 등 (0) | 2024.10.25 |
| 돌려보고 싶은데 귀찮아서 망설이고 있는 Human Detection Model MMPedestron (2) 좀 친해지려고 노력중 (0) | 2024.10.19 |
| 돌려보고 싶은데 귀찮아서 망설이고 있는 Human Detection Model MMPedestron (1) (0) | 2024.10.07 |
| 이미지 생성 모델 FLUX 맛보기 (2) | 2024.10.06 |
- Total
- Today
- Yesterday
- LCA
- 백트래킹
- FairMOT
- 조합
- 위상 정렬 알고리즘
- 백준
- 이분탐색
- 문제집
- cosine
- 단축키
- 백준 1766
- 순열
- 백준 11437
- Lowest Common Ancestor
- PyCharm
- ㅂ
- MOT
- 가장 긴 증가하는 부분 수열
- 인공지능을 위한 선형대수
- 백준 11053
- C++ Deploy
- 파이참
- 자료구조
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |||
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| 19 | 20 | 21 | 22 | 23 | 24 | 25 |
| 26 | 27 | 28 | 29 | 30 | 31 |